
AI Gateway - Część 1, Kontrola Dostępu
Czy wiesz, że APIM (Azure API Management) może być Twoim sprzymierzeńcem w zarządzaniu #OpenAI w firmie?
Usługa Azure API Management to hybrydowa platforma do zarządzania interfejsami API w środowiskach chmurowych i on-premises. Za jej pomocą wdrożysz zcentralizowany monitoring, zabezpieczysz swoje API, dodasz logikę ich wywołania i transformacji. Dodatkowo możesz zarządzać dokumentacją, wersjami, cyklem życia API w jednym miejscu, dostępnym dla potencjalnych odbiorców (programistów, którzy tych API używają).
APIM ❤️ OpenAI
No dobrze, ale jak ma się to do OpenAI?
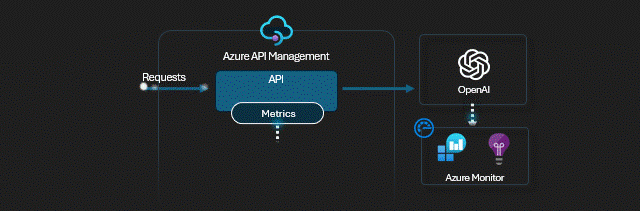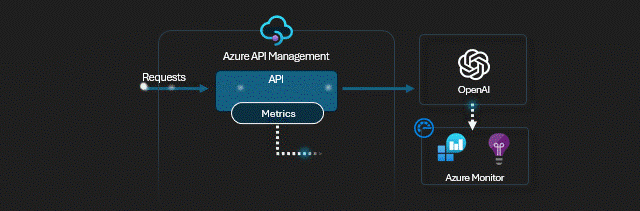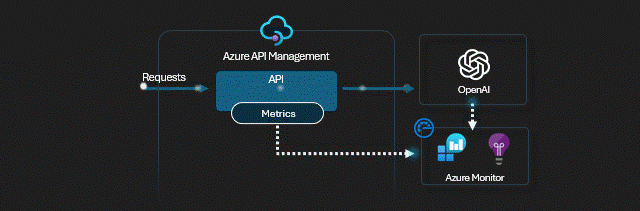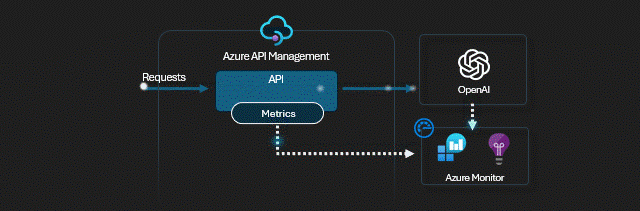
To proste, przecież OpenAI wystawia API, a przy jego pomocy wysyłasz do usługi prompty i otrzymujesz odpowiedzi. Zamiast wywoływać OpenAI API bezpośrednio z aplikacji, możesz je wywoływać za pośrednictwem APIMa, który automatycznie zaaplikuje wszystkie skonfigurowane przez Ciebie polityki na wejściu (request) i wyjściu (response) wywołania API.
W konsekwencji dostajemy zestaw narzędzi do “administrowania” naszymi instancjami OpenAI.
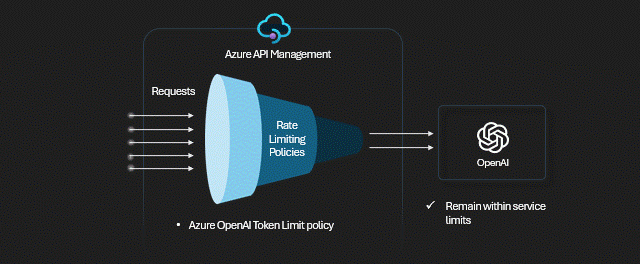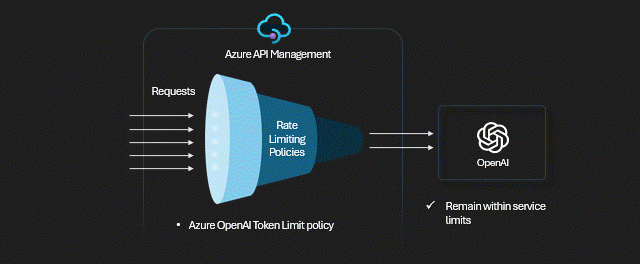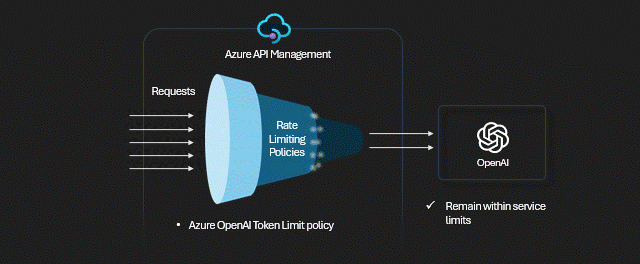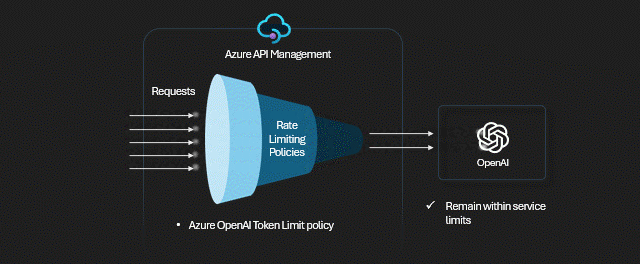
- Potrzebujesz limitów na ilość wywołań OpenAI z poszczególnych aplikacji, lub od określonych osób - pomoże polityka rate limiting lub quota.
- Chcesz rozrzucać ruch między wieloma instancjami OpenAI, a może potrzebujesz zaimplementować Circuit Breakera - nic prostszego.
- Chcesz rozliczyć kto ile skonsumował tokenów, lub zapisać treść promptów do logów - pomogą polityki logowania.
- Masz skomplikowane wymagania dotyczące uwierzytelniania i autoryzacji w Twojej organizacji lub aplikacji - APIM ma wbudowane mechanizmy walidacyjne i autoryzacyjne.
Scenariuszy może być znacznie więcej, ponieważ Microsoft mocno inwestuje w rozwój APIMa właśnie pod kątem jego użycia w kontekście usług AI.
Przykład: wbudowany w APIM semantyczny cache dla odpowiedzi - dla powtarzających się promptów (zbliżonych semantycznie) możemy serwować odpowiedzi bezpośrednio z cache APIMa, zamiast obciążać OpenAI.
Load Balancing OpenAI, po co?
W pierwszej części serii artykułów skoncentruję się na balansowaniu ruchu pomiędzy wieloma instancjami OpenAI.
Pewnie nasuwa Ci się pytanie po co wdrażać kilka instancji OpenAI? Odpowiedzi może być wiele, w zależności od architektury, oto kilka powodów:
- Microsoft wprowadził wiele limitów dotyczących liczby zapytań (RTM), tokenów (TPM), przepustowości. Limity mogą być liczone per instancję OpenAI, albo sumarycznie na wszystkie instancje w ramach pojedynczej subskrypcji/regionu. Rozwiązaniem może być kilka OpenAI wdrożonych tak, by te ograniczenia ominąć.
- W przypadku gdy zdecydujesz się na OpenAI w modelu PTU (provisioned throughput units) możesz w pewnym momencie przekroczyć założoną przepustowość. Wtedy z pomocą może przyjść druga instancja w modelu PAYG, by obsłużyć nadmiarową liczbę zapytań.
- Żadna usługa nie jest w stanie zagwarantować 100% dostępności. W przypadku Azure OpenAI Microsoft deklaruje w SLA trzy dziewiątki. W niektórych scenariuszach można wdrożyć APIMa w trybie multi-region wraz z dedykowanymi instancjami OpenAI. Dla pełnej jasności - APIM w jednym regionie ma SLA 99.95%, a w kilku 99.99%.
- Możemy wreszcie wysyłać ruch do Mocka - to w razie kompletnej katastrofy.
Load Balancing - wersja podstawowa
W podejściu pierwszym użyjemy funkcjonalności Backendu w APIM - od razu możemy też zaimplementować Circuit Breakera, poszalejmy :)
Backend możemy oczywiście wyklikać poprzez Portal Azure, ale ja preferuję automatyzację. Poniżej znajdziesz fragment kodu w bicep, który w pętli tworzy kilka backendów dla OpenAI w APIM (w zależności od liczby podanych instancji OpenAI).
resource backendOpenAI 'Microsoft.ApiManagement/service/backends@2023-05-01-preview' = [for (config, i) in openAIConfig: if(length(openAIConfig) > 0) {
name: config.name
parent: apimService
properties: {
description: 'backend description'
url: '${cognitiveServices[i].properties.endpoint}/openai'
protocol: 'http'
circuitBreaker: {
rules: [
{
failureCondition: {
count: 3
errorReasons: [
'Server errors'
]
interval: 'PT5M'
statusCodeRanges: [
{
min: 429
max: 429
}
]
}
name: 'openAIBreakerRule'
tripDuration: 'PT1M'
}
]
}
}
}]
resource backendPoolOpenAI 'Microsoft.ApiManagement/service/backends@2023-05-01-preview' = if(length(openAIConfig) > 1) {
name: openAIBackendPoolName
parent: apimService
properties: {
description: openAIBackendPoolDescription
type: 'Pool'
pool: {
services: [for (config, i) in openAIConfig: {
id: '/backends/${backendOpenAI[i].name}'
priority: config.priority
weight: config.weight
}
]
}
}
}
Istotny kawałek to ten, który zawiera kod błędu HTTP 429 “TooManyRequests” - skończyły się nam tokeny, pora na pominięcie tej instancji przez kolejną minutę.
Drugi istotny element to stworzenie backendu typu pool - ten umożliwia ustawianie priorytetów i wag pomiędzy poszczególnymi instancjami, ale też reaguje na ich niedostępność opisaną wcześniej.
Ostatni krok to wstawienie polityki APIM, która będzie przekierowywać żądania do naszej puli.
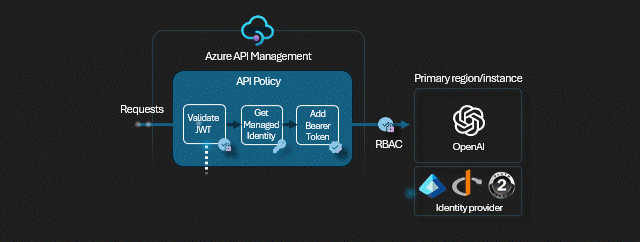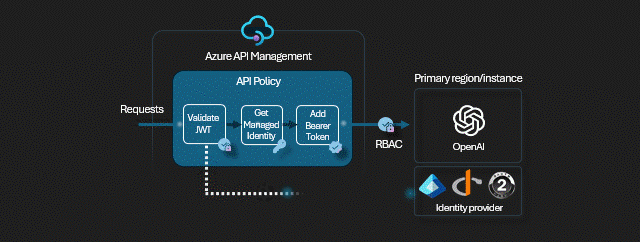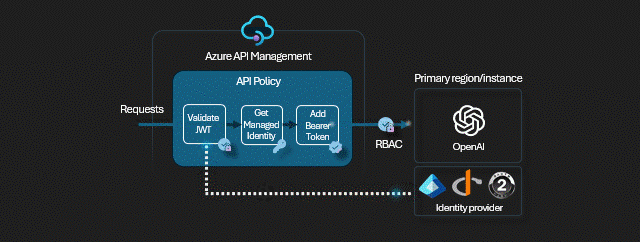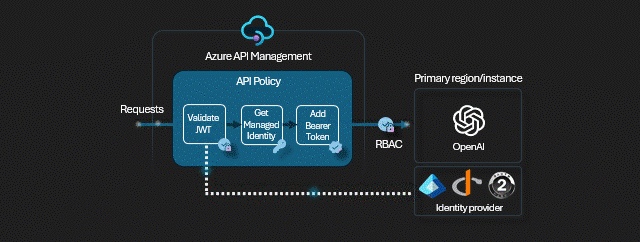
W tym miejscu przyda się drobna uwaga - każda z instancji OpenAI w teorii ma inny klucz, w praktyce odradzam używanie kluczy API. Zamiast kluczy używamy tożsamości pochodzących z Entra ID - w naszym scenariuszu to tożsamość APIMa (a konkretnie jego MSI - Managed Identity) ma uprawnienia na wszystkich instancjach OpenAI.
Tematy autoryzacji i uwierzytelniania pojawią się w kolejnych artykułach!
Oto kod polityki:
<policies>
<inbound>
<base />
<authentication-managed-identity resource="https://cognitiveservices.azure.com" output-token-variable-name="managed-id-access-token" ignore-error="false" />
<set-header name="Authorization" exists-action="override">
<value>@("Bearer " + (string)context.Variables["managed-id-access-token"])</value>
</set-header>
<set-backend-service backend-id="{backend-pool-id}" />
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
Load Balancing - wersja zaawansowana
Jeżeli powyższe rozwiązanie z jakiegoś powodu nie jest wystarczające w Twoim scenariuszu, możesz siegnąć do podejścia zaawansowanego. Kilka miesięcy temu Microsoft opublikował repozytorium Github z takim właśnie rozwiązaniem.
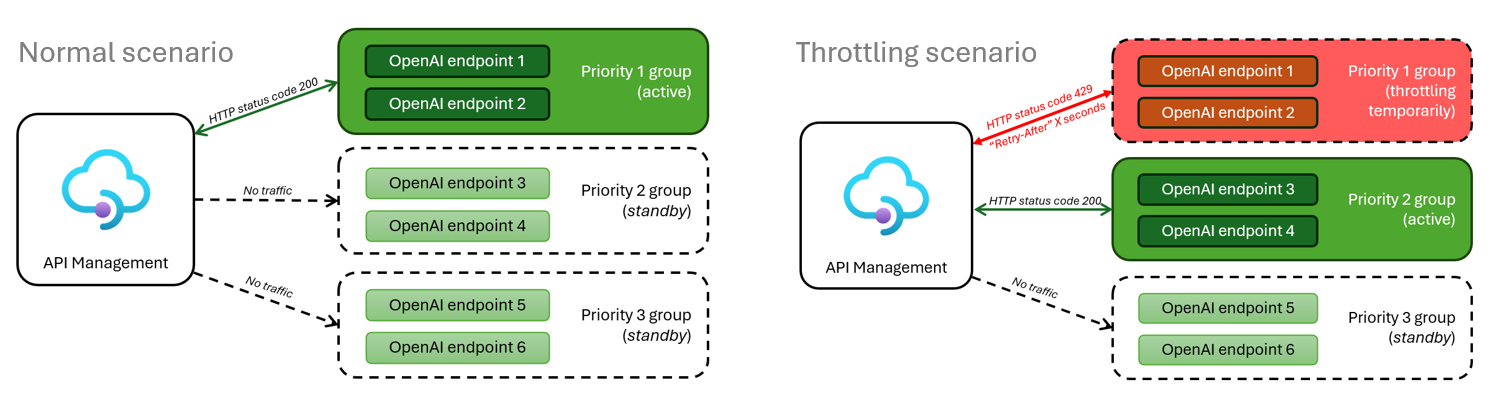
Rozwiązanie zapewnia wszechstronne podejście do problemów dostępności, kodów błędów, logowania, monitorowania i automatycznej konfiguracji. Zarządza dostępem do wielu instancji OpenAI uwzględniając priorytety, ich dostępność czy lokalizację.
Podsumowanie
W opisanych powyżej scenariuszach APIM pozwala nam wysyłać ruch na kilka instancji OpenAI w celu zwiększenia dostępności rozwiązania, ominięcia nałożonych przez Microsoft limitów, lub selektywnego użycia PTU i PAYG.
Zapraszam Cię do śledzenia mojego profilu LinkedIn i odkrywania, jak APIM może stać się Twoim sprzymierzeńcem w świecie AI. Do zobaczenia w następnych artykułach!
Comments